
Thursday, 4 February 2016
B1 Correlation
| Correlation Coefficient, r : |
the direction of a linear relationship between two variables. The linear correlation
coefficient is sometimes referred to as the Pearson product moment correlation coefficient in
honor of its developer Karl Pearson.

where n is the number of pairs of data.
(Aren't you glad you have a graphing calculator that computes this formula?)
linear correlations and negative linear correlations, respectively.
to +1. An r value of exactly +1 indicates a perfect positive fit. Positive values
indicate a relationship between x and y variables such that as values for x increases,
values for y also increase.
to -1. An r value of exactly -1 indicates a perfect negative fit. Negative values
indicate a relationship between x and y such that as values for x increase, values
for y decrease.
close to 0. A value near zero means that there is a random, nonlinear relationship
between the two variables
employed.
straight line. If r = +1, the slope of this line is positive. If r = -1, the slope of this
line is negative.
less than 0.5 is generally described as weak. These values can vary based upon the
"type" of data being examined. A study utilizing scientific data may require a stronger
correlation than a study using social science data.
B1 Skewness by Karl Pearson
What is Pearson’s Coefficient of Skewness?
- Pearson’s Coefficient of Skewness #1 uses the mode. The formula is:
Where= the mean, Mo = the mode and s = the standard deviation for the sample.
See: Pearson Mode Skewness. - Pearson’s Coefficient of Skewness #2 uses the median. The formula is:
Where
It is generally used when you don’t know the mode.
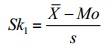
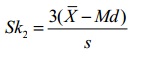
Sample problem: Use Pearson’s Coefficient #1 and #2 to find the skewness for data with the following characteristics:
- Mean = 70.5.
- Median = 80.
- Mode = 85.
- Standard deviation = 19.33.
Pearson’s Coefficient of Skewness #1 (Mode):
Step 1: Subtract the mode from the mean: 70.5 – 85 = -14.5.
Step 2: Divide by the standard deviation: -14.5 / 19.33 = -0.75.
Step 1: Subtract the mode from the mean: 70.5 – 85 = -14.5.
Step 2: Divide by the standard deviation: -14.5 / 19.33 = -0.75.
Pearson’s Coefficient of Skewness #2 (Median):
Step 1: Subtract the median from the mean: 70.5 – 80 = -9.5.
Step 2: Divide by the standard deviation: -9.5 / 19.33 = -1.47.
Step 1: Subtract the median from the mean: 70.5 – 80 = -9.5.
Step 2: Divide by the standard deviation: -9.5 / 19.33 = -1.47.
Caution: Pearson’s first coefficient of skewness uses the mode. Therefore, if the mode is made up of too few pieces of data it won’t be a stable measure of central tendency. For example, the mode in both these sets of data is 9:
1 2 3 4 5 6 7 8 9 9.
1 2 3 4 5 6 7 8 9 9 9 9 9 9 9 9 9 9 9 9 10 12 12 13.
In the first set of data, the mode only appears twice. This isn’t a good measure of central tendency so you would be cautioned not to use Pearson’s coefficient of skewness. The second set of data has a more stable set (the mode appears 12 times). Therefore, Pearson’s coefficient of skewness will likely give you a reasonable result.
1 2 3 4 5 6 7 8 9 9.
1 2 3 4 5 6 7 8 9 9 9 9 9 9 9 9 9 9 9 9 10 12 12 13.
In the first set of data, the mode only appears twice. This isn’t a good measure of central tendency so you would be cautioned not to use Pearson’s coefficient of skewness. The second set of data has a more stable set (the mode appears 12 times). Therefore, Pearson’s coefficient of skewness will likely give you a reasonable result.
B1 Problems In The Construction Of Index Numbers
Problems In The Construction Of Index Numbers
Before constructing index numbers a careful thought must be given the following problems:1. The purpose of the index.
At the very outset the purpose of constructing the index must be very clearly, decided – what the index is to measures and why? There is no all-purpose index. Every index is of limited and particular use. Thus, a price index that is intended to measure consumers’ prices must not include wholesale prices. And if such an index in intended to measure the cost of living of poor families, great care should be taken not to include goods ordinarily used by middle class and upper-income groups.2. Selection of a base period.
Whenever index numbers are constructed a reference is made to some base period. The base period of an index number (also called the reference period) is the period against which comparisons are made.(I) THE BASE PERIOD SHOULD BE NORMAL ONE.
The period that is selected as base should be normal, i.e., it should be free from abnormalities like wars, earthquakes, famines, booms, depressions, etc. However, at times it is really difficult to select year which is normal in al respects – a year which is normal in one respect may be abnormal in another.(II) THE BASE PERIOD SHOULD NOT BE TOO DISTANT IN THE PAST.
It is desirable to have an index based on a fairly recent period, since comparison with a familiar set of circumstances is more helpful than comparison with vaguely remembered conditions.(III) FIXED BASE OR CHAIN BASE.
While selecting the base a decision has to be made as to whether the base shall remain fixed or not, i.e., whether we have a fixed base or chain base index.3. Selection of number of items.
The items included in an index should be determined by the purpose for which the index is constructed. Every item cannot be included while constructing an index number and hence once has to select a sample. It is also necessary to decide the grade or quality of the items to be included in the index. Index numbers shall give wrong result if at one time one set of qualities is included and at another time another set.4. Price quotations.
After the commodities have been selected, the next problem is to obtain price quotations for these commodities. It is a will known fact that prices of many commodities vary from place to place and even from shop to shop in the same market. It is impracticable to obtain price quotations from all the places where a commodity is dealt in. A selection must be made of representative places and persons. These places should be those which are well known for trading for that particular commodity.5. Choice of an Average.
Theoretically speaking, geometric mean is the best average in the construction of index numbers because of following reasons: (i) in the constructions of index number we are concerned with ratios of relative changes and the geometric mean gives equal weights to equal ratio of change; (ii) geometric mean is less susceptible to major variations as a result of violent fluctuations in the values of the individual items; and (iii) index numbers calculated by using the average are reversible and, therefore, base shifting is easily possible. The geometric mean index always satisfies the time reversal test.6. Selection of appropriate weights.
The problem of selecting suitable weights in quite important and at the same quite difficult to decide. The term ‘weight’ refers to the relative importance and hence it is necessary to devise some suitable method whereby the varying importance of the different items by taken into account. This is done by allocating weights. Thus, in the former case, no specific weights are assigned whereas in the latter case specific weights are assigned to various items. It may be pointed out here that no index is unweighted in strict sense of the term as weights implicitly enter the unweighted indices because we are giving equal importance to all the items and hence weights are unity. It is, therefore, necessary to adopt some importance to all the items and hence weights are unity. It is, therefore, necessary to adopt some suitable method of weighting so that arbitrary and haphazard weights may not affect the results. There are two methods of assigning weights: (i) implicit, and (ii) explicit.7. Selection of an appropriate formula.
A large number of formulae have been devised for constructing the index. The problem very often is that of selecting the most appropriate formula. The choice of the formula would depend not only on the purpose of the index but also on the data available.B1 Dispersion and skewness
S.No
|
Dispersion
|
Skewness
|
1
|
It is concerned
with measuring the amount of variation in a series rather than with its
direction
|
It is concerned
with the variation or the departure from symmetry
|
2
|
It tells us about composition of the
series
|
It tells about the shape of the
series
|
3
|
Measures of
dispersion are based on averages of the first order such as K, M, Z etc
|
Measure of skewness
arc based on averages of the first and second order such as X, M, Z etc
|
What is the difference between Dispersion and Skewness?
Dispersion concerns about the range over which the data points are distributed, and the skewness concerns the symmetry of the distribution.
Both measures of dispersion and skewness are descriptive measures and coefficient of skewness gives an indication to the shape of the distribution.
Measures of dispersion are used to understand the range of the data points and offset from the mean while skewness is used for understanding the tendency for the variation of data points into a certain direction.
B1 Limitation of statistics
The important limitations of statistics are:
(1) Statistics laws are true on average. Statistics are aggregates of facts. So single observation is not a statistics, it deals with groups and aggregates only.
(2) Statistical methods are best applicable on quantitative data.
(3) Statistical cannot be applied to heterogeneous data.
(4) It sufficient care is not exercised in collecting, analyzing and interpretation the data, statistical results might be misleading.
(5) Only a person who has an expert knowledge of statistics can handle statistical dataefficiently.
(6) Some errors are possible in statistical decisions. Particularly the inferential statistics involves certain errors. We do not know whether an error has been committed or not
Statistics
- Variable
- Characteristic or attribute that can assume different values
- Random Variable
- A variable whose values are determined by chance.
- Population
- All subjects possessing a common characteristic that is being studied.
- Sample
- A subgroup or subset of the population.
- Parameter
- Characteristic or measure obtained from a population.
- Statistic (not to be confused with Statistics)
- Characteristic or measure obtained from a sample.
- Descriptive Statistics
- Collection, organization, summarization, and presentation of data.
- Inferential Statistics
- Generalizing from samples to populations using probabilities. Performing hypothesis testing, determining relationships between variables, and making predictions.
- Qualitative Variables
- Variables which assume non-numerical values.
- Quantitative Variables
- Variables which assume numerical values.
- Discrete Variables
- Variables which assume a finite or countable number of possible values. Usually obtained by counting.
- Continuous Variables
- Variables which assume an infinite number of possible values. Usually obtained by measurement.
- Nominal Level
- Level of measurement which classifies data into mutually exclusive, all inclusive categories in which no order or ranking can be imposed on the data.
- Ordinal Level
- Level of measurement which classifies data into categories that can be ranked. Differences between the ranks do not exist.
- Interval Level
Level of measurement which classifies data that can be ranked and differences are meaningful. However, there is no meaningful zero, so ratios are meaningless. - Ratio Level
- Level of measurement which classifies data that can be ranked, differences are meaningful, and there is a true zero. True ratios exist between the different units of measure.
- Random Sampling
- Sampling in which the data is collected using chance methods or random numbers.
- Systematic Sampling
- Sampling in which data is obtained by selecting every kth object.
- Convenience Sampling
- Sampling in which data is which is readily available is used.
- Stratified Sampling
- Sampling in which the population is divided into groups (called strata) according to some characteristic. Each of these strata is then sampled using one of the other sampling techniques.
- Cluster Sampling
- Sampling in which the population is divided into groups (usually geographically). Some of these groups are randomly selected, and then all of the elements in those groups are selected.
Tuesday, 2 February 2016
Business Organisation and Management
22.Techniques of coordination:-
Sound planning
sound and simple organisation
chain of command
effective communication
committees
conferences
Social coordinaions
sound leadership
Problems of coordination:-
Uncertainity
Biological
Organisaional limits
Coordination:- orderly arrangement of group efforts to provide unity of action in the pursuit of a common purpose
Leaderahip:-process of influencing others towards the accomplishment of goals
21. Importance of controlling:
Aids planning
Improves efficiency
Aids decision making
Aids coordination
Improves
Techniques of control:-
Budgetary control
Standard Costing
Brrak-even analysis
PERT/CPM
Return on investment
Budget:- A blue print of a projected course of action, stated in quantitative terms.
Controlling:- The process of setting standard of performance measuring and comparing actual performance with the standard, taking corrective action when necessary
Subscribe to:
Comments (Atom)

-
Benefits of GST | Advantages of Goods and Services Tax Updated on May 26, 2017 - 03:23:54 PM The Goods & Service Tax or GST ...

